Common database concepts
Introduction
If you’re following the DFTW curriculum, we started with associative arrays in PHP to introduce basic key-value pairs concepts, then moved to JSON for handling semi-structured data (with slightly clearer syntax). You can explore most of the data architecture concepts just with JSON. And by now, you’re probably diving into SQL and “relational” databases.
We’ll explore official document-based databases and some more full-featured cloud suites as we continue, but it’s nice to just stay high-level and focus on the ideas and not the details of Object-Relational Mapping (ORM) tools just yet.
“Relational” refers to databases based on Relational Algebra (from Edgar Codd), not just linked tables. Document-based databases offer flexibility, while table-based databases are effective for structured data. Table-based and document-based databases can be relational, so terms like “relational” and “non-relational” are incorrect.
These concepts are dead simple if you let them be. Take it slow and try it all out. Ignore any hype about which databases are “cool” at the moment and focus on what matters.
Defining concepts
// Define the basic entities and their attributes
// OK we're going to be modeling out a monster adoption agency
// and maybe they'll share their favorite food
// and we'll need to keep track of their progress and record that somehow
MONSTER:
id: unique identifier
name: string
age: number?
adopted: boolean / true/false or a date?
date_entered: date / when they were checked in / found
favorite_foods: list of FOODs?
friends: list of MONSTER ids?
FOOD:
id: unique identifier
name: string
REPORT:
id: unique identifier
monster_id: MONSTER id
content: string
FRIENDS?
?The computer/program doesn’t know anything you don’t explain. Neither do your coworkers. So, as simple as it sounds – you 100% have to define everything (explicitly).
It’s fun. You are the creator. What are you going to create?
"Tables" vs "document Collections"
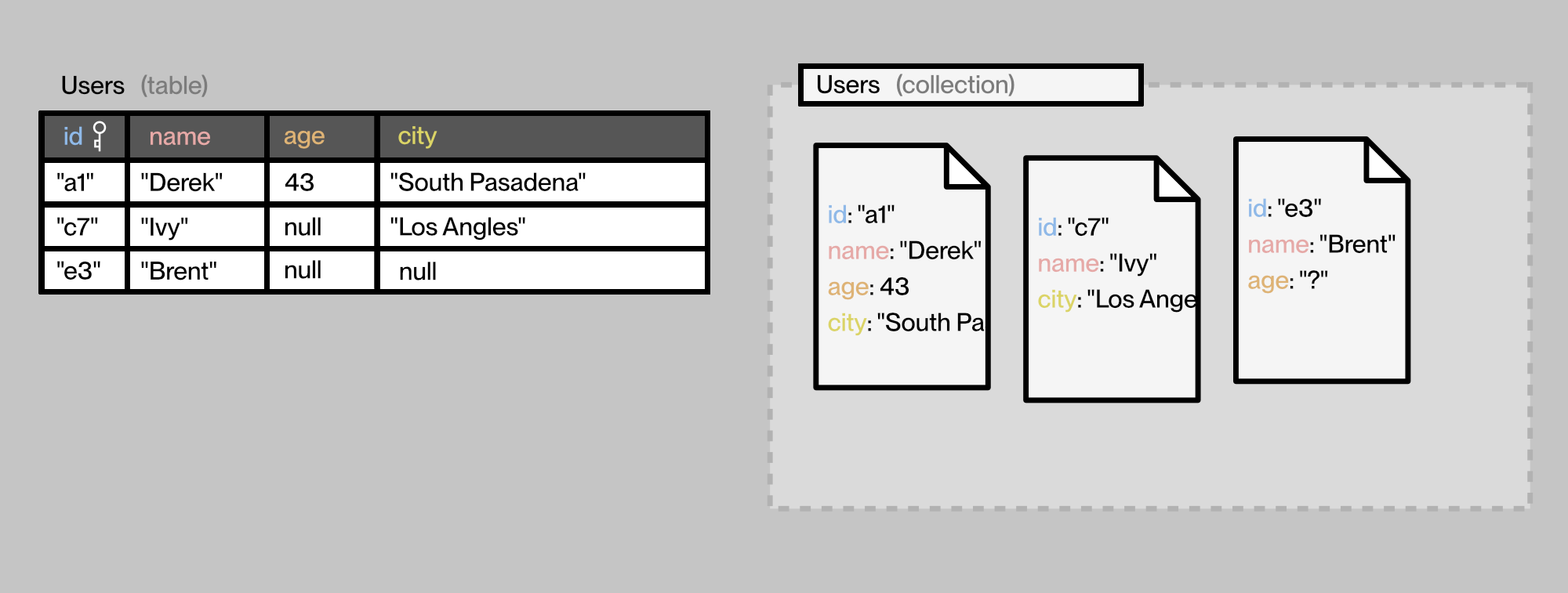
We’ll show some real representations at the end, but hopefully, these will help you get a mental picture going.
Records
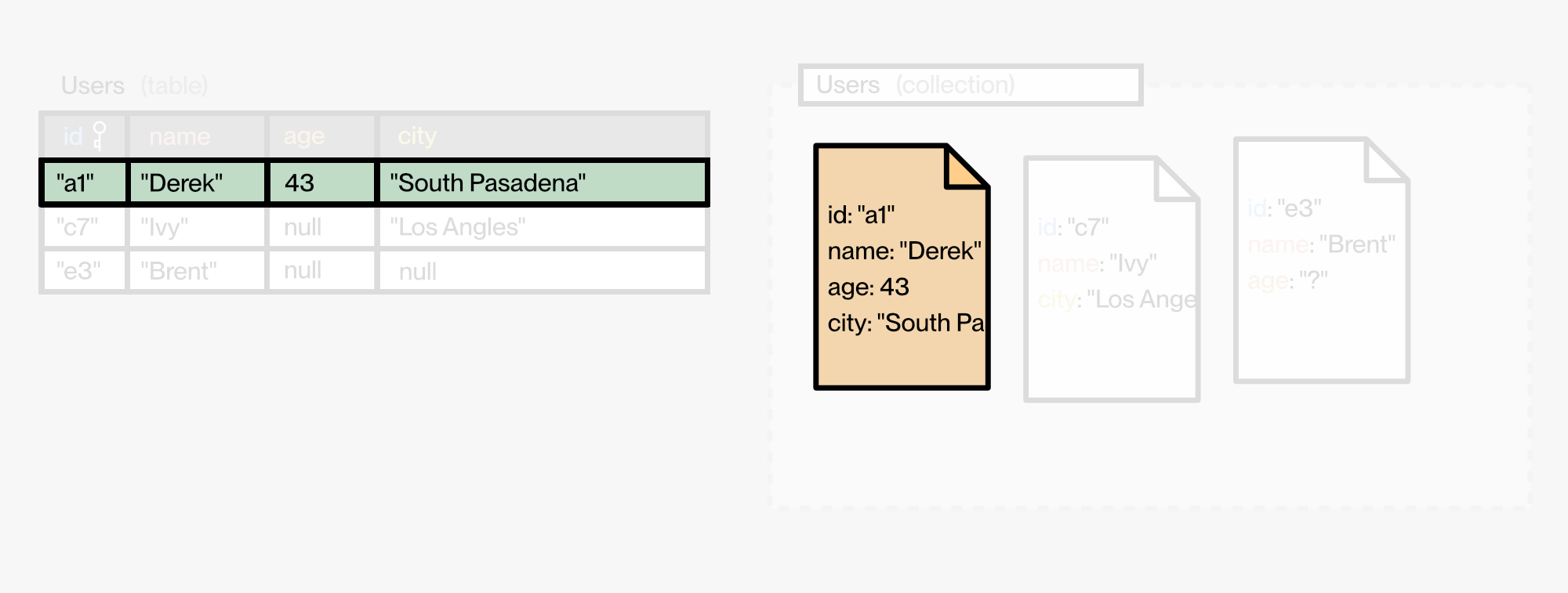
Yes, they are different… But if you aren’t using both simultaneously, there’s no great reason to differentiate. We can just call them “records.”
Basic data storage (Single records and lists)
{
"id": 1,
"title": "Monster Adoption Agency",
"description": "Find your perfect monster companion today!",
"last_updated": "2024-09-20"
}[
{
"id": 1,
"name": "Fluffy",
"age": 200,
"adopted": false,
"date_entered": "2024-01-15"
},
{
"id": 2,
"name": "Spike",
"age": 350,
"adopted": true,
"date_entered": "2023-11-23"
},
{
"id": 3,
"name": "Grizzle",
"age": 50,
"adopted": false,
"date_entered": "2024-02-01"
}
]{
"a27": {
"name": "Fluffy",
"age": 200,
"adopted": false,
"date_entered": "2024-01-15"
},
"b31": {
"name": "Spike",
"age": 350,
"adopted": true,
"date_entered": "2023-11-23"
},
"e76": {
"name": "Grizzle",
"age": 50,
"adopted": false,
"date_entered": "2024-02-01"
}
}Concept: At the most basic level, data is stored as individual records. You can retrieve either a single record by its unique ID or a complete list of records.
Document-Based: Each record is stored as a document in a collection (e.g., a monster document in a monsters collection).
Table-Based: Each record is stored as a row in a table (e.g., a monster in a monsters table).
| id | name | age | adopted | date entered |
|---|---|---|---|---|
| 1 | Fluffy | 200 | False | 2024-01-15 |
| monsters | ||||
|---|---|---|---|---|
| id | name | age | adopted | date entered |
| 1 | Fluffy | 200 | False | 2024-01-15 |
| 2 | Spike | 350 | True | 2023-11-23 |
| 3 | Grizzle | 50 | False | 2024-02-01 |
Question: But where? (also – we should probably add a note about schema and how these columns have specific datatypes set)
To start, you can manually write out this data. But pretty quickly, you’re going to want to build out some forms so that users can start adding their own data and test the app.
English: Add a new monster named “Bruno,” aged 150, not adopted yet.
SQL:
INSERT INTO monsters (name, age, adopted)
VALUES ('Bruno', 150, false);
Doc: db.monsters.insertOne({ name: 'Bruno', age: 150, adopted: false });
| monsters | ||||
|---|---|---|---|---|
| id | name | age | adopted | date entered |
| 1 | Fluffy | 200 | False | 2024-01-15 |
| 2 | Spike | 350 | True | 2023-11-23 |
| 3 | Grizzle | 50 | False | 2024-02-01 |
| 4 | Bruno | 150 | False | 2024-04-01 |
And you might realize that there is no Bruno! And you need to update the record. Or that there is a Bruno – but you didn’t know because they got adopted already.
English: Update Bruno’s adoption status
SQL:
UPDATE monsters
SET adopted = true
WHERE id = 4; -- Using Bruno's ID
Doc: db.monsters.updateOne({ id: 4 }, { $set: { adopted: true } });
| monsters | ||||
|---|---|---|---|---|
| id | name | age | adopted | date entered |
| 1 | Fluffy | 200 | False | 2024-01-15 |
| 2 | Spike | 350 | True | 2023-11-23 |
| 3 | Grizzle | 50 | False | 2024-02-01 |
| 4 | Bruno | 150 | True | 2024-04-01 |
Or maybe it turned out Bruno was all in your imagination, and you need to delete that record.
English: Remove Bruno
SQL:
DELETE FROM monsters
WHERE id = 4;
Doc: db.monsters.deleteOne({ id: 4 });
| monsters | ||||
|---|---|---|---|---|
| id | name | age | adopted | date entered |
| 1 | Fluffy | 200 | False | 2024-01-15 |
| 2 | Spike | 350 | True | 2023-11-23 |
| 3 | Grizzle | 50 | False | 2024-02-01 |
But maybe… you don’t really want to fully “delete” it and instead do some form of “soft delete.”
English: Mark Bruno as “archived” so we can recover his record later if needed
SQL:
ALTER TABLE monsters ADD archived BOOLEAN DEFAULT false;
UPDATE monsters
SET archived = true
WHERE id = 4;
Doc: db.monsters.updateOne({ id: 4 }, { $set: { archived: true } });
| monsters | |||||
|---|---|---|---|---|---|
| id | name | age | adopted | date entered | archived |
| 1 | Fluffy | 200 | False | 2024-01-15 | False |
| 2 | Spike | 350 | True | 2023-11-23 | False |
| 3 | Grizzle | 50 | False | 2024-02-01 | False |
| 4 | Bruno | 150 | False | 2024-04-01 | True |
Getting the data
<?php
// You're going to have to get the data from somewhere
// it might be in files somewhere
// we're going to assume it's already retrieved
// PHP: Retrieving data from a file (synchronous)
$json = file_get_contents('data/monsters.json'); // Waits until done
$monsters = json_decode($json, true); // Decodes into an associative arrayIf you have access to the file system, then it’s quick work to get something real working. PHP is synchronous, so it waits for each operation to finish before moving on.
// JavaScript: Asynchronous data retrieval
async function getMonsters() {
const response = await fetch('https://jsonplaceholder.typicode.com/posts');
const monsters = await response.json();
return monsters;
}
const monsters = await getMonsters(); // Needs to be inside an async function
// This needs to be in an async function to work
// --- feel free to ignore this stuff
// Assuming monsters.json is already globally available as database.monsters
let monsters = database.monsters;
// Log or use the data
console.log( monsters );JavaScript is asynchronous, meaning it doesn’t wait for operations like fetch() to finish. This adds complexity because you need asynchronous handling mechanisms like promises and async/await. That’s not what we’re talking about here (But so that you can see what it might look like).
The learning curve for server-side JavaScript makes it a bad place to start (in our opinion), but you can keep things on the client side with just a few leaps of faith. For this conversation, let’s assume the data is retrieved and readily available in these examples, OK? That will keep the focus on the concepts (not the implementation).
Concept: Data is typically retrieved from files or databases. The process will vary depending on your environment, but the goal remains consistent—access and manipulate your data, whether it’s stored in a local file, a database, or even a global variable.
Let’s assume data like database.monsters is already available globally in our examples. Focus on the concepts rather than the specific syntax or how the data is retrieved.
English: I'd love a list of all the monsters, please
SQL: SELECT * FROM monsters;
Doc: db.monsters.find({});
Rendering
<?php
foreach ($monsters as $monster) {
// render each monster and a link to their detail page
}monsters.forEach( function(monster) {
// render each monster and a link to their detail page
});Concept: Once the data is retrieved, the next step is often rendering it on a page, typically in a list format. Each item will have a link to its corresponding detail page, allowing users to explore more information.
(Just to remind you of what you’ll likely do with the data)
You’re probably going to have a list page where you display products, cars, teams, or monsters. This list acts as an index, allowing users to click and request individual detail pages for specific items. Each page will show more detailed information about a single record.
Getting a single record
<?php
$singleMonster = null;
foreach ($monsters as $monster) {
if ($monster['id'] === 1) {
$singleMonster = $monster;
break;
}
}let singleMonster = null;
monsters.forEach( function(monster) {
if (monster.id === 1) {
singleMonster = monster;
}
});Concept: When working with your data, you’ll often need to retrieve one specific record, typically based on an ID or uuid or slug. Whether you’re working with an array in PHP, JavaScript, or querying a database, the approach remains consistent—find the unique record by its identifier.
After listing all records, you’ll likely want a detail page for each item. When a user clicks a monster on the list page, they expect to see more details about that specific monster. The way we retrieve that single record in PHP or JavaScript is very similar. And there are convenience functions like array_search() and array.find()
English: I want to see the details for just one monster—here’s the ID
SQL: SELECT * FROM monsters WHERE id = 1;
Doc: db.monsters.findOne({ id: 1 });
Basic Filtering (finding records)
$filtered = array_filter($monsters, function($monster) {
return !$monster['adopted'];
});
// or shorthand
$filtered2 = array_filter($monsters, fn($monster) => !$monster['adopted']);let filtered = monsters.filter( function(monster) {
return !monster.adopted;
// Filtering for monsters not yet adopted
});
// or shorthand
let filtered2 = monsters.filter( (monster)=> !monster.adopted);NOTE: We’re using a JavaScript example (even though you might not have worked with JS yet; we’re assuming you’ve worked with this much PHP, and we’re just highlighting how similar they are).
Concept: Filtering records lets you pull out data that meets certain conditions (like finding all monsters that haven’t been adopted yet). It’s key for narrowing down big datasets to just the stuff you care about.
If you already have all the data, you can sort it yourself. But if you’re asking for sorted data, the server will take care of that before sending it back to you.
English: Show me all the monsters that haven’t been adopted yet.
SQL: SELECT * FROM monsters WHERE adopted = false;
Doc: db.monsters.find({ adopted: false });
Sorting and Advanced Filtering
// Filter for monsters not adopted, and sort by 'date_entered'
let filteredAndSortedMonsters = monsters
.filter( (monster)=> !monster.adopted)
.sort( (a, b)=> new Date(a.date_entered) - new Date(b.date_entered));
console.log(filteredAndSortedMonsters);// Here's where it flips... and the PHP is just too ugly... : /
// so, from here on out - we'll stick with shorthand JS examplesConcept: In more advanced scenarios, you might need to filter records by multiple conditions and sort them by a certain attribute. Sorting lets you arrange records in a meaningful order (e.g., by signup date), while filtering narrows the dataset.
English: Find all the monsters that aren’t adopted yet and show them to me, starting with the ones added the longest time ago.
SQL:
SELECT * FROM monsters
WHERE adopted = false
ORDER BY date_entered ASC;
doc:
db.monsters
.find({ adopted: false })
.sort({ date_entered: 1 });
Relationships (One-to-Many)
[
{
"id": 1,
"name": "Fluffy"
},
{
"id": 2,
"name": "Spike"
},
{
"id": 3,
"name": "Grizzle"
}
][
{
"id": 1,
"monster_id": 1,
"report": "Fluffy stole all the marshmallows!"
},
{
"id": 3,
"monster_id": 2,
"report": "Spike accidentally set the kitchen on fire!"
},
{
"id": 2,
"monster_id": 1,
"report": "Fluffy turned invisible and scared the staff."
},
{
"id": 4,
"monster_id": 2,
"report": "Spike knocked over the water tower while flying."
},
{
"id": 5,
"monster_id": 3,
"report": "Grizzle climbed to the top of the building and refused to come down!"
}
]let fluffyReports = reports.filter( (report)=> report.monster_id === 1);Concept: A one-to-many relationship connects each monster to multiple incident reports. A monster can have many reports, but each report references only one monster.
| monsters | ||
|---|---|---|
| id | name | |
| 1 | Fluffy | |
| 2 | Spike | |
| 3 | Grizzle | |
| reports | ||||
|---|---|---|---|---|
| id | monster_id | content | ||
| 1 | 1 | Fluffy stole all the marshmallows! | ||
| 3 | 2 | Spike accidentally set the kitchen on fire! | ||
| 2 | 1 | Fluffy turned invisible and scared the staff. | ||
| 4 | 2 | Spike knocked over the water tower while flying. | ||
| 5 | 3 | Grizzle climbed to the top of the building. | ||
English: Get all the reports written about Fluffy.
SQL: SELECT * FROM reports WHERE monster_id = 1;
Doc: db.reports.find({ monster_id: 1 });
Complex Relationships (Many-to-Many)
[
{
"id": 1,
"name": "Fluffy",
"favorite_foods": [1, 2]
},
{
"id": 2,
"name": "Spike",
"favorite_foods": [2, 3]
},
{
"id": 3,
"name": "Grizzle",
"favorite_foods": [1]
}
][
{
"id": 1,
"food": "Marshmallows"
},
{
"id": 2,
"food": "Honey"
},
{
"id": 3,
"food": "Spicy Tacos"
}
]Concept: Many-to-many relationships allow multiple entities on both sides to be associated with one another. In this case, a monster can have many favorite foods, and a food can be the favorite of many monsters.
| monsters | ||
|---|---|---|
| id | name | favorite_foods |
| 1 | Fluffy | 1, 2 |
| 2 | Spike | 2, 3 |
| 3 | Grizzle | 1 |
| foods | |
|---|---|
| id | name |
| 1 | Marshmallows |
| 2 | Honey |
| 3 | Spicy Tacos |
English: List all of Fluffy’s favorite foods.
SQL:
SELECT foods.name FROM foods
JOIN monster_foods ON foods.id = monster_foods.food_id
WHERE monster_foods.monster_id = 1;
The join is basically a temporary table that is created with those two – which is then used to run the query. Note the automatic naming conventions.
| monster_foods | |
|---|---|
| monster_id | food_id |
| 1 | 1 |
| 1 | 2 |
| 2 | 2 |
| 2 | 3 |
| 3 | 1 |
Doc: db.monsters.find({ id: 1 }, { favorite_foods: 1 });
Complex Relationships (junctions)
[
{
"id": 1,
"name": "Fluffy",
"favorite_foods": [1, 2]
},
{
"id": 2,
"name": "Spike",
"favorite_foods": [2, 3]
},
{
"id": 3,
"name": "Grizzle",
"favorite_foods": [1]
}
][
{
"id": 1,
"monster_id": 1,
"friend_id": 2
},
{
"id": 2,
"monster_id": 1,
"friend_id": 3
},
{
"id": 3,
"monster_id": 2,
"friend_id": 3
}
]Concept: A many-to-many relationship is often used to represent friendships or associations between entities of the same type (e.g., monsters and other monsters). This is done using a junction table that references both monster IDs.
English: Find all the monsters who are friends with Fluffy.
Up until now, the table-based and document-based examples have been largely similar in how they retrieve data. Whether we were filtering, sorting, or finding single records, both approaches used fairly equivalent methods with comparable levels of complexity.
SQL:
SELECT * FROM friendships
JOIN monsters ON friendships.friend_id = monsters.id
WHERE friendships.monster_id = 1;
Doc:
db.friendships.find({ monster_id: 1 }, { friend_id: 1 });
db.monsters.find({ id: { $in: [ /* previous query */ ] } });
Relational databases allow for more complex queries like JOINs, while document-based databases typically require multiple queries for related data, offering more flexibility but potentially more complexity when retrieving related documents.
| monsters | |||
|---|---|---|---|
| id | name | ||
| 1 | Fluffy | ||
| 2 | Spike | ||
| 3 | Grizzle | ||
| 4 | Bruno | ||
| friendships | ||
|---|---|---|
| id | monster_id | friend_id |
| 1 | 1 | 2 |
| 2 | 1 | 3 |
| 3 | 2 | 3 |
| 4 | 4 | 3 |
And you’ll need to allow users to add their friends.
English: Make Bruno friends with Grizzle using their IDs
SQL:
INSERT INTO friendships (monster_id, friend_id)
VALUES (4, 3); -- Bruno's ID is 4, Grizzle's ID is 3
Doc:
db.friendships.insertOne({ monster_id: 4, friend_id: 3 });
Some examples
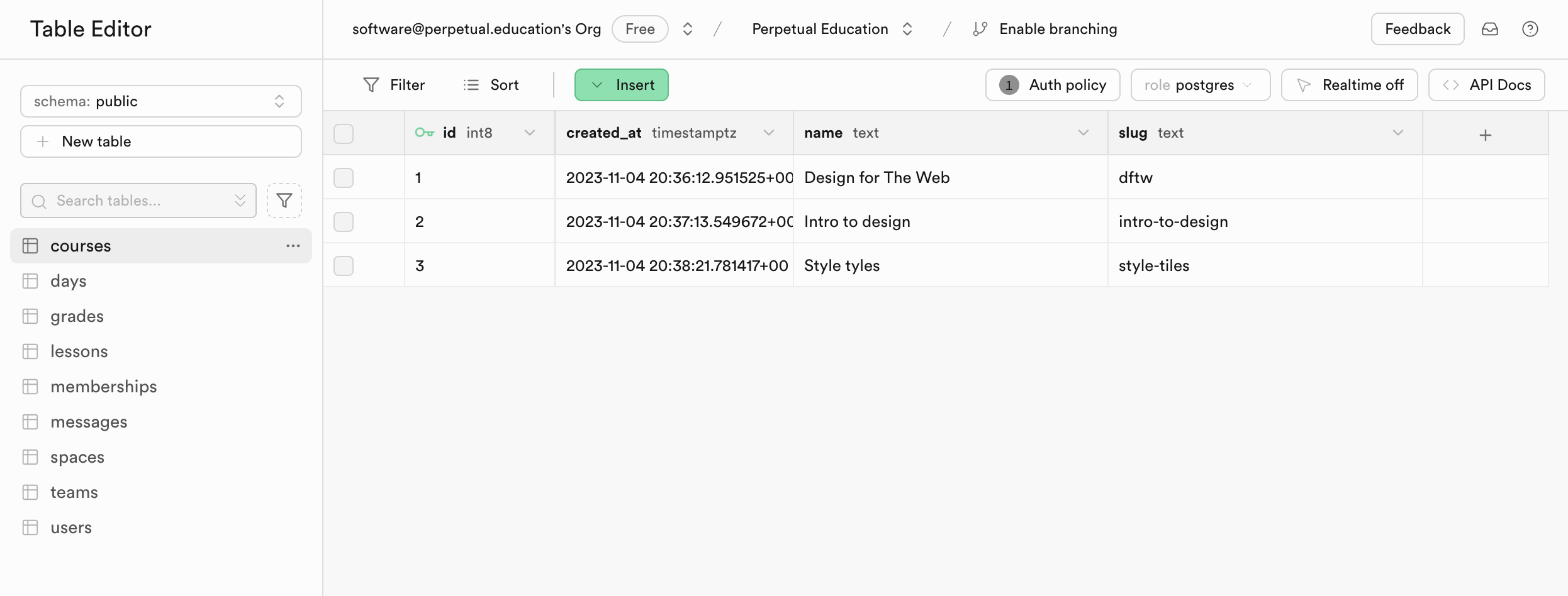
Here’s a Supabase (cloud database) table showing how that UI might look.
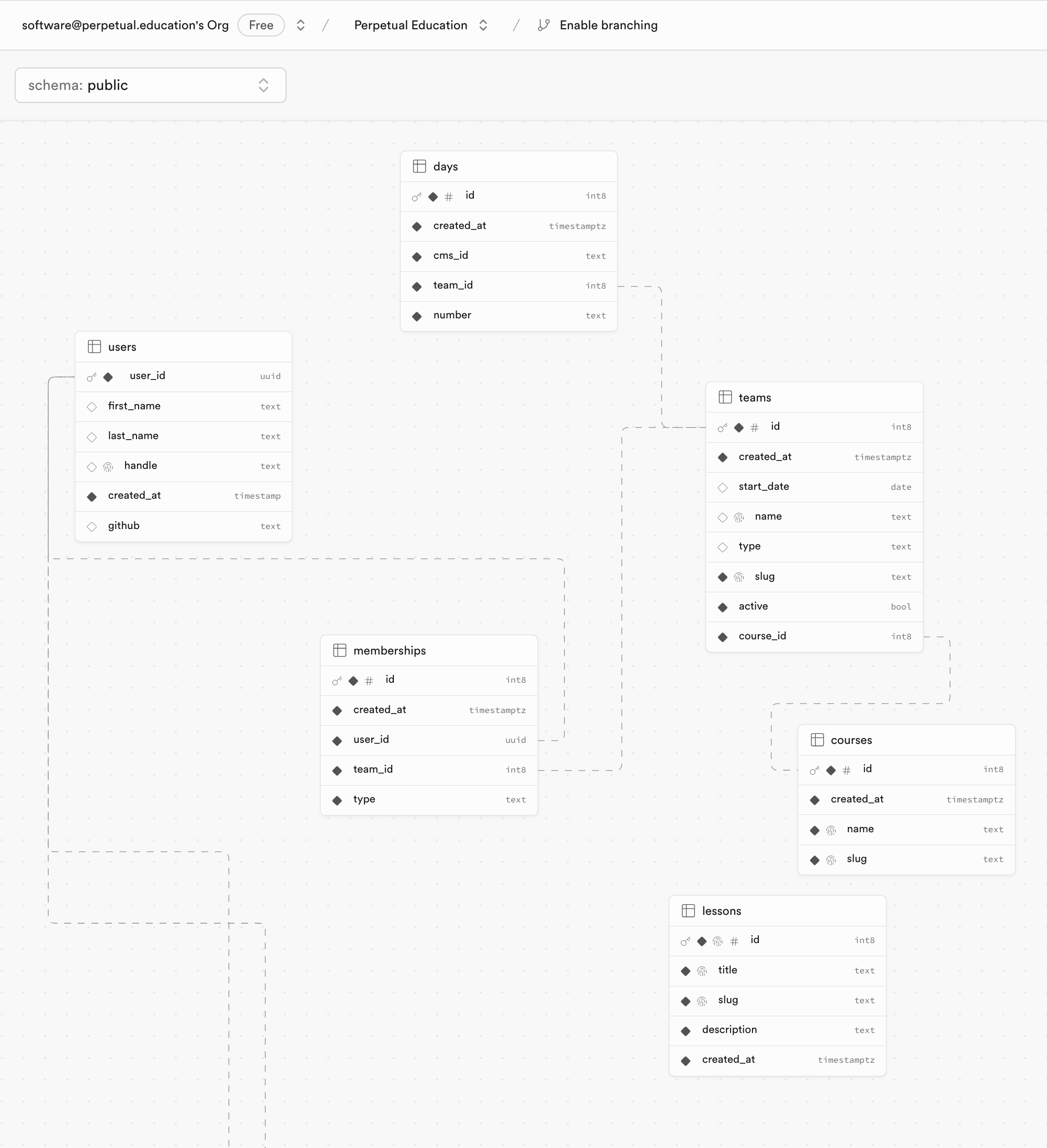
Sometimes, they give you this fun Schema view.
Firestore
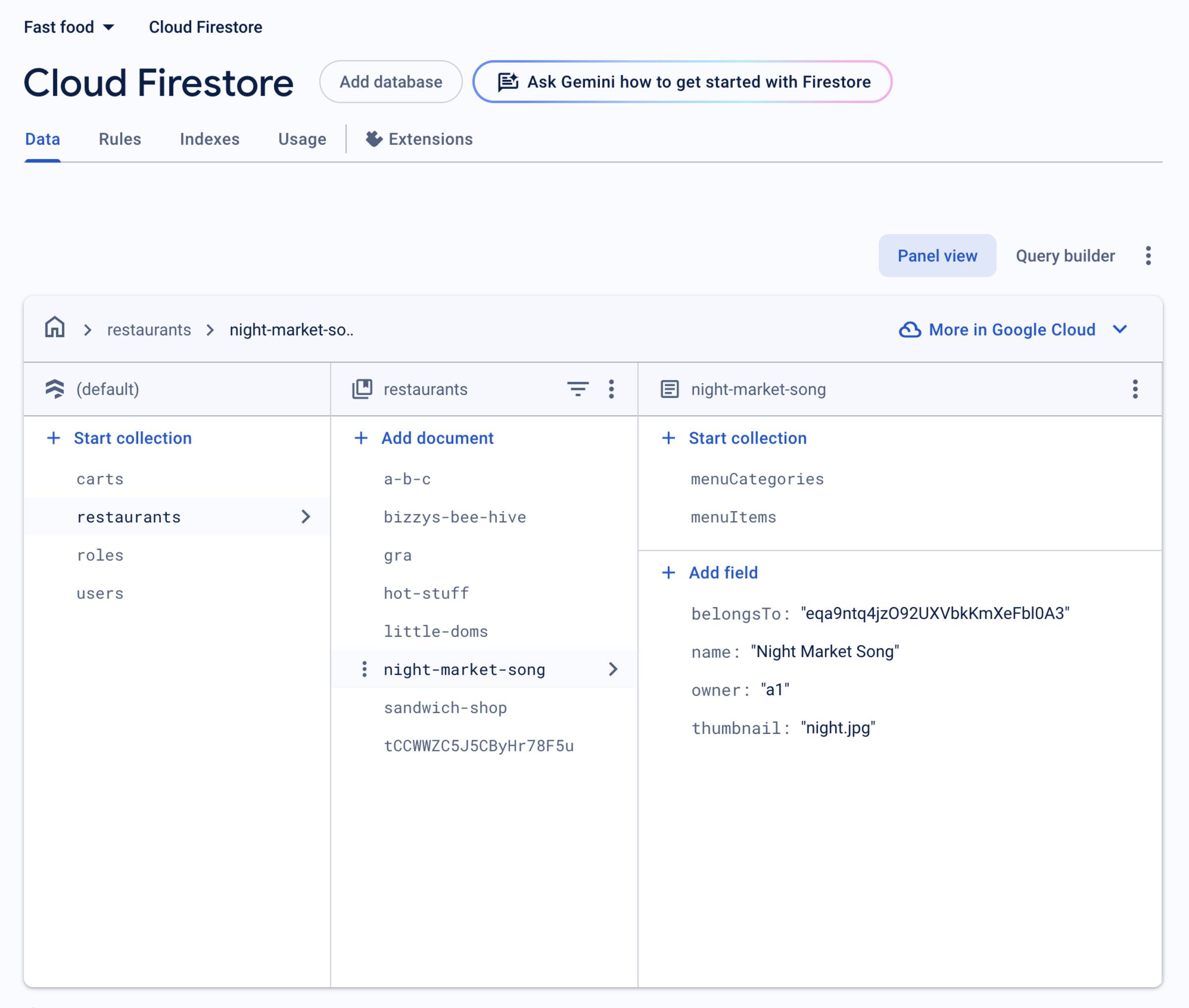
Here’s how Google’s document-based cloud database UI looks.
If you complete the challenge…
Let us know and we’ll send you a link to part 2.
- Data Consistency
- Eventual vs strong consistency
- Handling updates across multiple records
- Caching
- Techniques to reduce load (e.g., in-memory caches)
- Polymorphic Associations
- Flexible relationships (e.g., comments can belong to multiple entities)
- Indexes
- Basic and secondary indexes for performance optimization
- Aggregation
- Summing, counting, and grouping data
- Transactions
- Ensuring atomic operations (e.g., multi-step actions like adopting a monster and updating records)
- Sharding and Scaling
- Handling large-scale data with sharding and replication
What do you think? Was this interesting?
If you’re interested in this way of explaining things, we’ve got hundreds more like it. Consider one of our coaching programs or a self-guided version of DFTW.